
How JavaScript works: an overview of the engine, the runtime, and the call stack
很基础的一篇文章,就当复习英语了😂
随着 JavaScript 越来越热门,越来越多的团队开始尝试在其它方向上使用它- 前端、后端、混合型应用、嵌入式应用等等.
这篇文章是这个系列的第一篇,目标是对 JavaScript 的工作机制进行深入挖掘: 通过了解 JavaScript 的构建原理和工作机制,你就能够写出更好的代码和应用;我们也会分享一些我们团队构建 SessionStack 时的经验法则,它是一个轻量的 JavaScript 应用,有着良好的鲁棒性和高可用性来应对竞争;
就像 GitHut stats所展示的那样,JavaScript 在 Github 的 活跃仓库和 Total Push 排名上都是第一;其它方面的排名也低不到哪去;
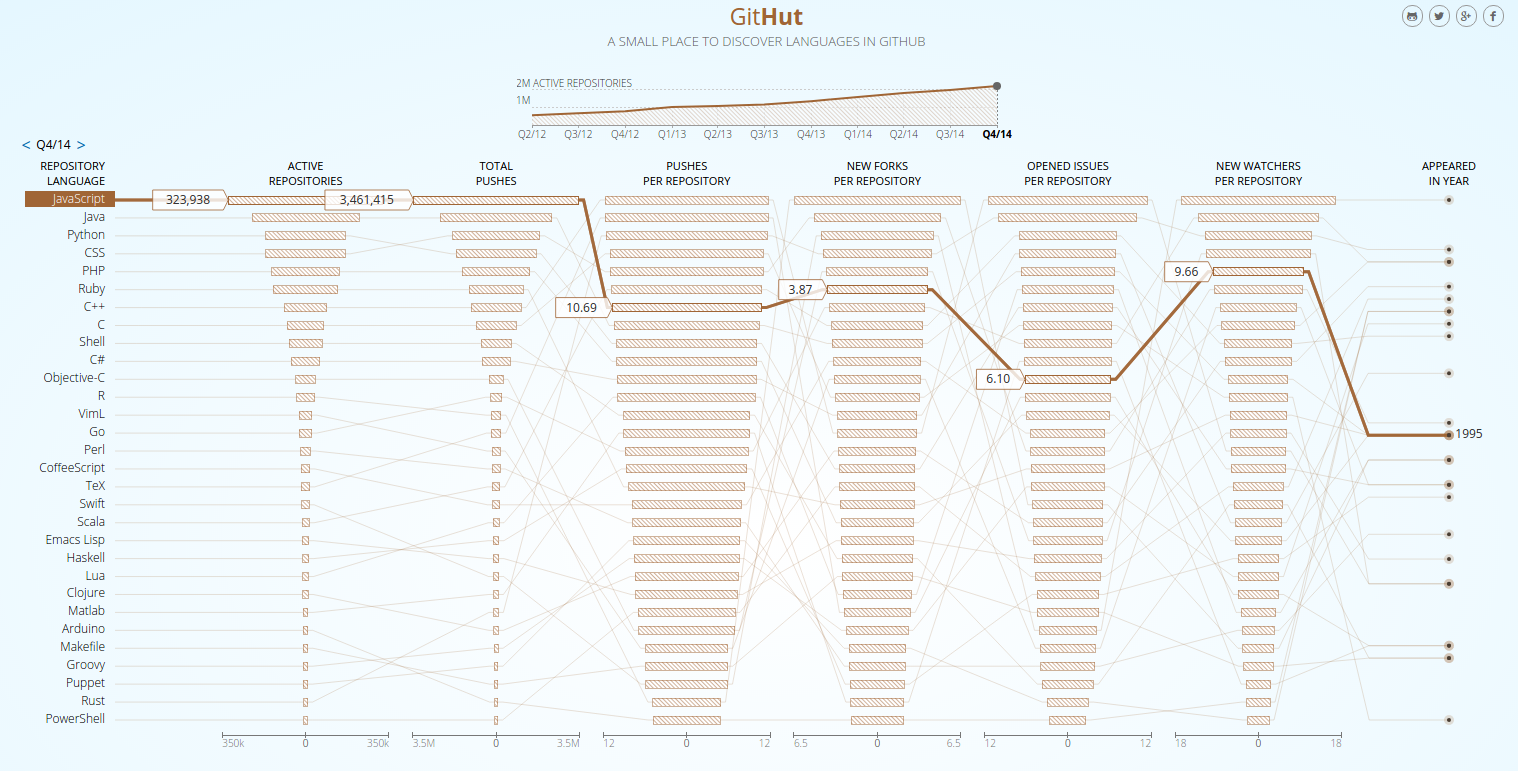
如果项目越来越依赖于 JavaScript,这意味着开发者必须非常深入语言的内在来优化这门语言和它的生态系统,这样才能构建出优秀的软件.
所以,有许多开发者日常使用 JavaScript 只是停留在表层上,并没有深入了解引擎背后发生了什么.
概览
每个人都或多或少听说过 V8 引擎,有更多人知道 JavaScript 是一门单线程或者说采用回调队列的语言;
这系列文章中,我们会详细探讨这些概念的细节,解释 JavaScript 到底是怎么运行的.知道这些细节以后,你就能借用已提供的 API 写出更好、非阻塞式的应用;
如果你对 JavaScript 并不是很了解,这篇文章会让你知道为什么 JavaScript 和其他语言相比是那么地『怪异』;
如果你已经是一名熟练的 JavaScript 开发者,这篇文章会给你关于你每天都在用的 JavaScript 运行时的一些新的见解;
JavaScript 引擎
JavaScript 引擎最出名的例子就是谷歌的 V8 Engine.V8 Engine 被用在 Chrome 浏览器以及 Node.js 平台上.这里可以简要地了解一下它是怎么样的:
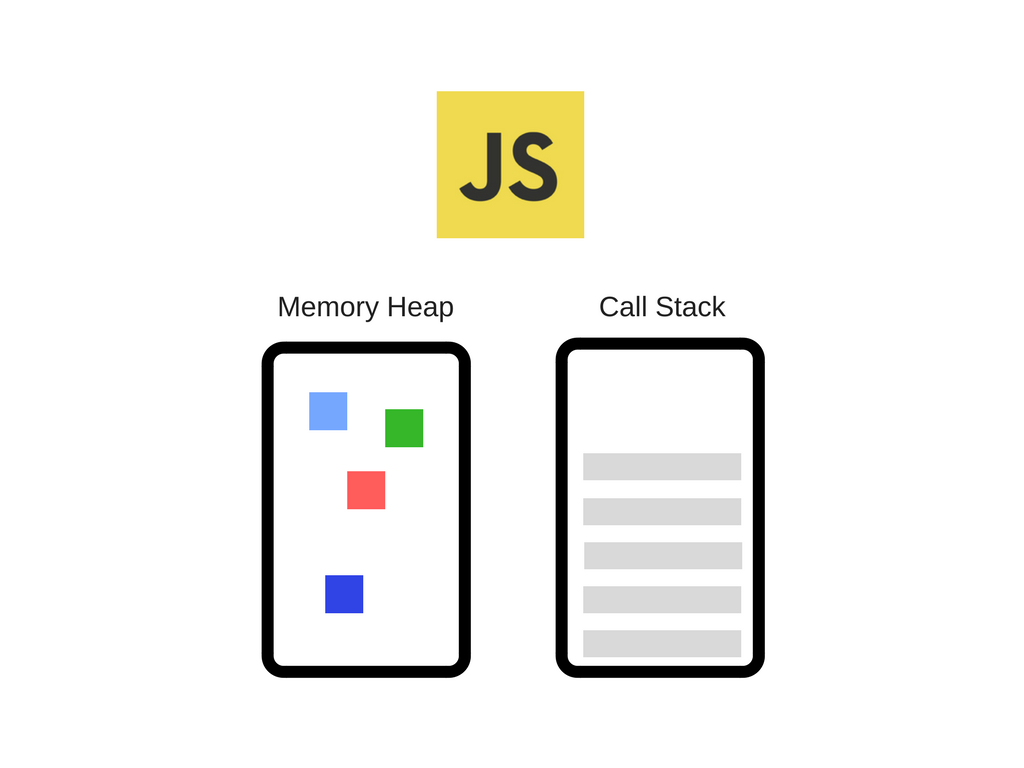
JavaScript 引擎有两大主要部分:
- 内存堆(Memory Heap)–这是内存分配进行的地方
- 调用栈(Call Stack)–这是你代码运行时记录栈帧 / 活动记录 (stack frame)的地方
运行时
大多数 JavaScript 开发者都用过一些 API,比如『setTimeout』,然而这并不是 JavaScript 引擎提供的.
那这些 API 从哪来呢?
答案有点点复杂:
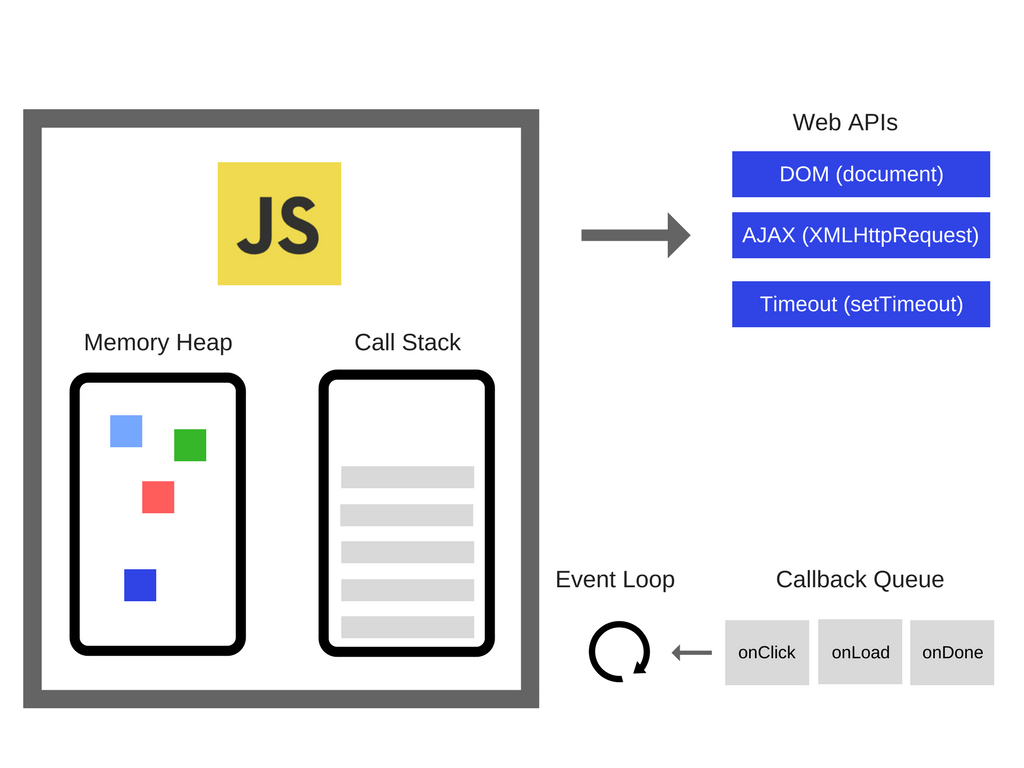
所以,虽然我们已经有了 JavaScript 引擎,但其实还有很多东西提供背后支持;我们把这些浏览器提供的额外功能叫做 Web APIs,像是 DOM、AJAX、setTimeout 等等之类的.
调用栈
JavaScript 是一门单线程的编程语言,这意味着它只有一个调用栈;因此它一次只能执行一个任务;
调用栈是一个记录程序运行位置的数据结构;当我们进入一个函数时,便会将它(的活动对象)推入栈顶.当我们从一个函数中 return 后,就会将这个函数从栈顶弹出;这就是调用栈干的事情;
举个例子,看下面的代码:
1 | function multiply(x, y) { |
当 JavaScript 引擎开始执行上述代码时,栈是空的,然后会发生下面这些:

图中每一个调用栈的状态被称为一个栈帧 / 活动记录.
这也是异常被抛出时栈的 trace 构造–就是基于异常发生时栈的状态:
1 | function foo() { |
在 Chrome 中运行这段 foo.js 文件,堆栈跟踪的结果就是这样:
『溢栈』–这种情况发生在你突破了调用栈的最大容量时.这种情况很容易发生,尤其是你写了一段递归的代码(而且没有进行很好测试)时;
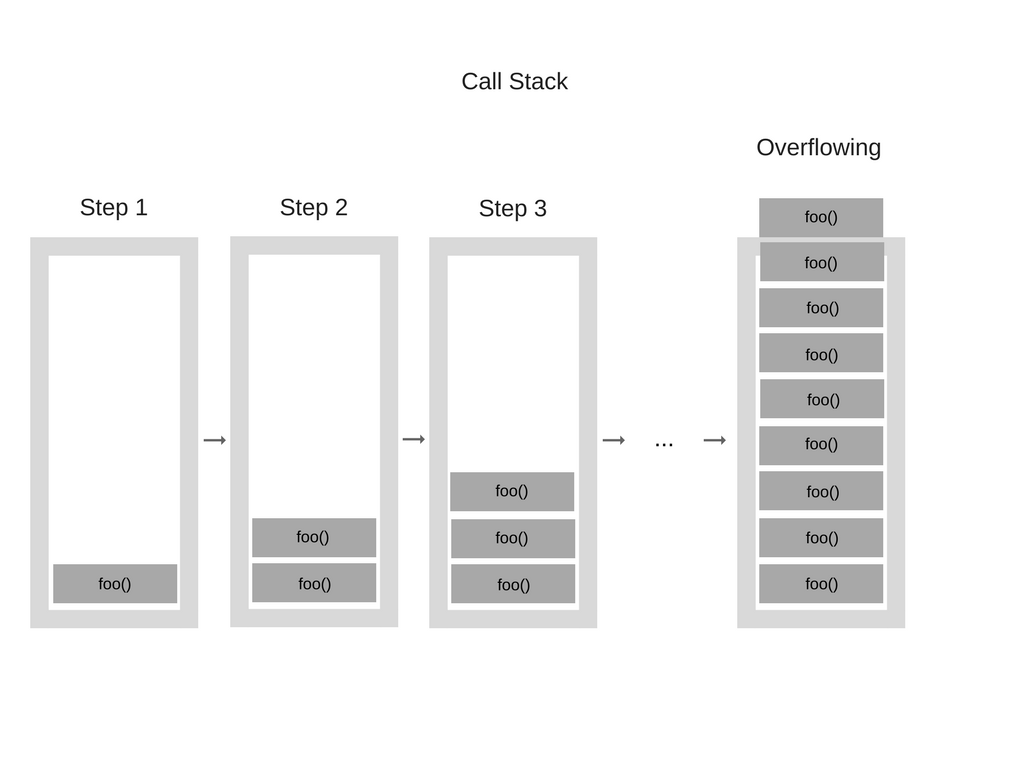
在某个时候,调用的函数数量超出了调用栈的容量,浏览器决定不能坐视不管,就会抛出一个错误:
在单线程语言中跑代码很容易,因为你不会遇到多线程场景中可能出现的问题,比如死锁;
然而单线程语言也存在着限制,因为 JavaScript 只有一个调用栈,那当一个任务执行的非常慢时会发生什么呢?
并发 & 事件循环
如果你的调用栈目前栈顶的函数需要花超多时间来执行时会发生什么?比如,你想要用 JavaScript 在浏览器上整一些很复杂的图像变换;
你可能会问–这也算问题吗? 是的,因为调用栈在执行函数时,浏览器是不能做任何事情的–换而言之,它被阻塞了;这意味着浏览器不能进行渲染,不能跑其它代码,它就堵在那;如果你的 app 需要一个好的响应式布局时,这就会导致很多问题;
这还不是唯一的问题 ,一旦你的浏览器往调用栈中推入超多任务,你的浏览器可能一段时间内都会停止响应;大多数浏览器会在这时候抛出一个错误,询问你是否要停止这个 web page.

这种情况下,还有什么用户体验这种说法吗?
所以,我们怎样才能执行一些复杂的代码而不会阻塞掉 UI 或者让浏览器停止响应呢?答案是使用异步回调(asynchronous callbacks),这部分的内容会在 Inside the V8 engine + 5 tips on how to write optimized code这篇教程中提到.
我们下次再见~